Szybkość inferencji zwiększa możliwości systemów AI
Zwiększenie szybkości inferencji modelu językowego nie jest jedynie poprawą komfortu użytkownika. Zmienia ono rodzaj systemów, które można by zbudować wokół modelu.
Już w 2024 Groq‑owe Llama 3.3 70B osiągał (1665 tokens/s z speculative decoding) i dziś w 2026 inne podobne stosy realnie zmieniają klasę możliwych pętli agentowych do poziomu, gdzie LLM przestaje być "wolną zewnętrzną usługą", a staje się komponentem sterowania o takcie liczonym w sekundach lub nawet ułamkach sekundy.
Pojawia się Mercury 2 jako lider output throughput z wynikiem 842 tok/s. W innym rankingu z 2025 roku wskazywany jest też Llama 4 Scout jako najszybszy model frontier-class, z deklarowanym throughputem 2,600 tok/s i TTFT 0.33 s
src: https://llm-stats.com/ https://www.cerebras.ai/press-release/llama4PR
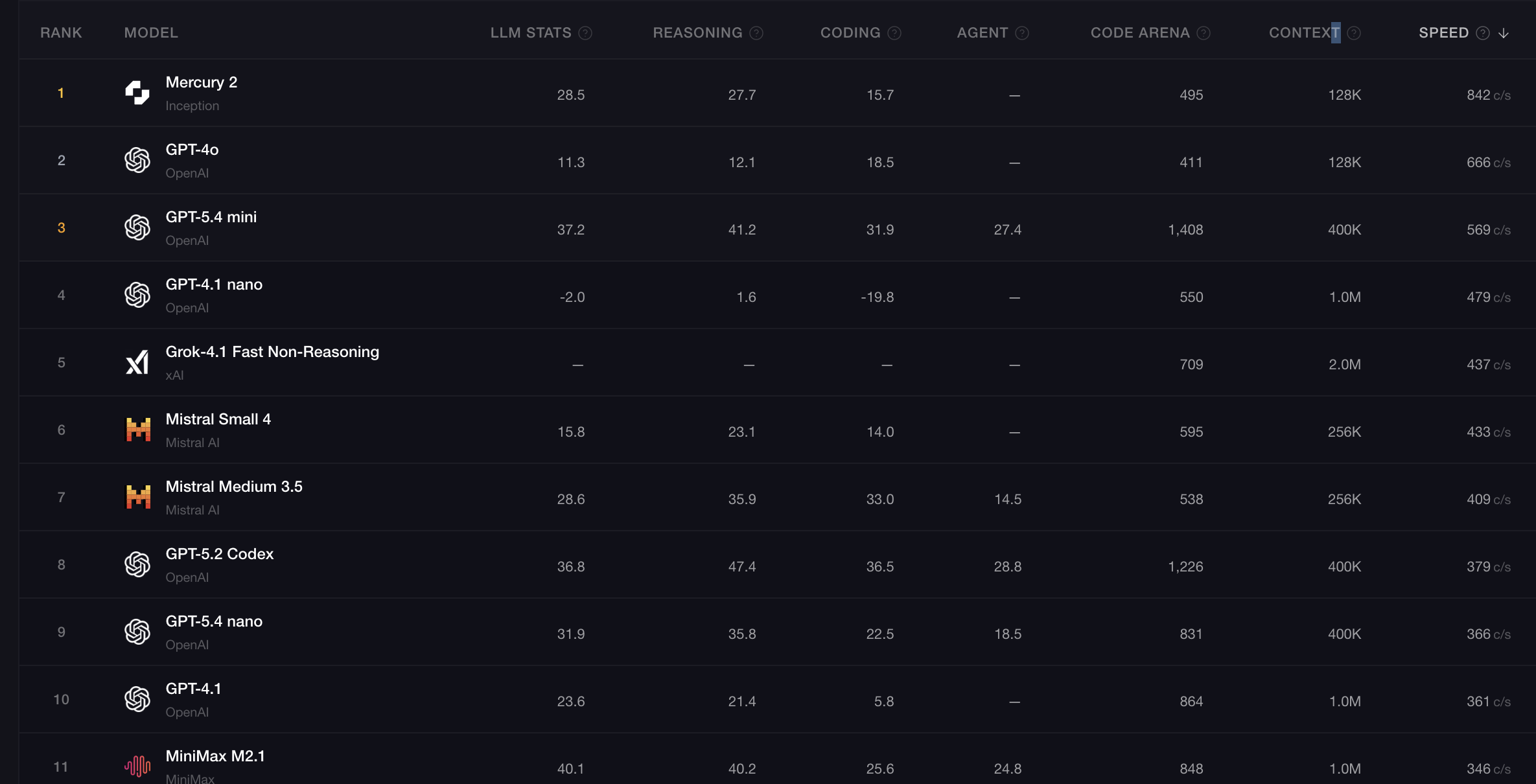
Model generujący setki tokenów na sekundę może wykonać więcej iteracji rozumowania, przeanalizować kilka możliwych rozwiązań, wielokrotnie używać narzędzi, uruchamiać testy, poprawiać błędy i nadal zwrócić wynik w akceptowalnym czasie.
Dlatego istotną miarą nie jest wyłącznie inteligencja widoczna w pojedynczej odpowiedzi, lecz ilość użytecznej pracy poznawczej, jaką model może wykonać w określonym czasie.
Szybsza inferencja zmienia sposób działania systemów AI:
- pętle agentów mogą działać interaktywnie zamiast asynchronicznie,
- błędne próby stają się tańsze
- analiza kodu, wyszukiwanie błędów, używanie narzędzi i sprawdzanie zmian może odbywać się bez przerywania toku pracy użytkownika,
- AI może przejść od modelu "pytanie-odpowiedź" do ciągłego lub niemal ciągłego uczestnictwa
- możliwe staje się analizowanie większej liczby alternatywnych rozwiązań w tym samym czasie.
Sama szybkość generowania tokenów nie jest jednak wystarczająca. Bardzo szybki, ale słaby model może generować duże ilości błędnych lub nieprzydatnych treści.
Praktyczna wartość inferencji zależy od połączenia:
Value = capability×speed×context capacity×reliability×cost
Oznacza to, że 15000 tokenów na sekundę generowanych przez słaby model może być mniej użyteczne niż 750 tokenów na sekundę generowanych przez frontier model. Podobnie szybki model z małym oknem kontekstowym może źle sprawdzać się w pracy agentowej, w której trzeba zachować kod, historię rozmowy, wyniki narzędzi i poprzednie decyzje.
Głębszą konsekwencją architektoniczną jest to, że odpowiednio szybkie modele mogą przestać pełnić rolę zewnętrznych usług, z których korzysta się sporadycznie. Mogą stać się aktywnymi elementami w skomplikowanych systemach.
- obserwować stan systemu,
- oceniać, czy potrzebna jest reakcja
- używać narzędzi
- sprawdzać rezultat
- powtarzać proces.
Szybkość inferencji modeli językowych (tokens/s, latency do pierwszego tokena) osiągnęła w ostatnich latach skokową poprawę dzięki specjalizowanemu hardware’owi (np. Groq LPU) oraz optymalizacjom po stronie modeli i runtime’u. Frontierowe modele oferują dziś nie dziesiątki a setki tokenów na sekundę przy sub-sekundowym czasie do pierwszego tokena, co czyni wielokrotne iteracje rozumowania i intensywne użycie narzędzi praktycznie wykonalnymi w czasie interakcji człowieka.
Ile "pracy poznawczej" w jednostce czasu
Iteracje reasoning i narzędzia
Przy throughput 800 tokens/s model może w ciągu 5 sekund wygenerować ~4000 tokenów, co pozwala na kilka pełnych chain‑of‑thought, kilkukrotne wywołanie narzędzi (np. HTTP, kod, RAG) i wygenerowanie hipotez przed zwróceniem odpowiedzi użytkownikowi. Frontierowe modele z throughput ~100 tokens/s wygenerują w tym samym czasie ok. 500 tokenów, co jest wystarczające na 2-3 iteracje reasoning i kilka wywołań narzędzi, zachowując nadal interakcyjność.cubed+4
W praktyce benchmarki agentowych frameworków pokazują, że przy throughput rzędu 50-100 tokens/s agenci mogą wykonywać 5-15 kroków (planowanie, narzędzia, walidacja, korekta) w czasie poniżej 10-15 s, co jest akceptowalne dla większości workflow developerskich i analitycznych. Przy szybkościach rzędu 500-800 tokens/s ta sama liczba kroków mieści się w 2-4 s, co umożliwia niemal ciągłe "udoskonalanie" systemu przez AI.