LLaVA-v1.5-13B: An Overview - Note
LLaVA-v1.5-13B: Integrating Language and Vision in AI
Developed in September 2023, the LLaVA-v1.5-13B model represents a significant advancement in artificial intelligence, combining language processing and image analysis.
Training and Development
LLaVA-v1.5-13B’s development involved fine-tuning on the LLAMA2 model, enhancing its language processing capabilities. The training data included:
- 558K Filtered Image-Text Pairs: Sourced from LAION/CC/SBU, captioned by BLIP.
- 158K GPT-Generated Multimodal Instructions: Combining language and visual elements.
- 450K Academic-Task-Oriented VQA Data: Focused on visual question answering.
- 40K ShareGPT Data: Providing diverse training points.
Licensing
- Based on LLAMA2 - Llama 2 is available for free for research and commercial use.
- Open-Source: The model’s source code and training data are publicly available for community use and enhancement.
- Apache 2.0 License: This allows for both research and commercial applications.
Performance
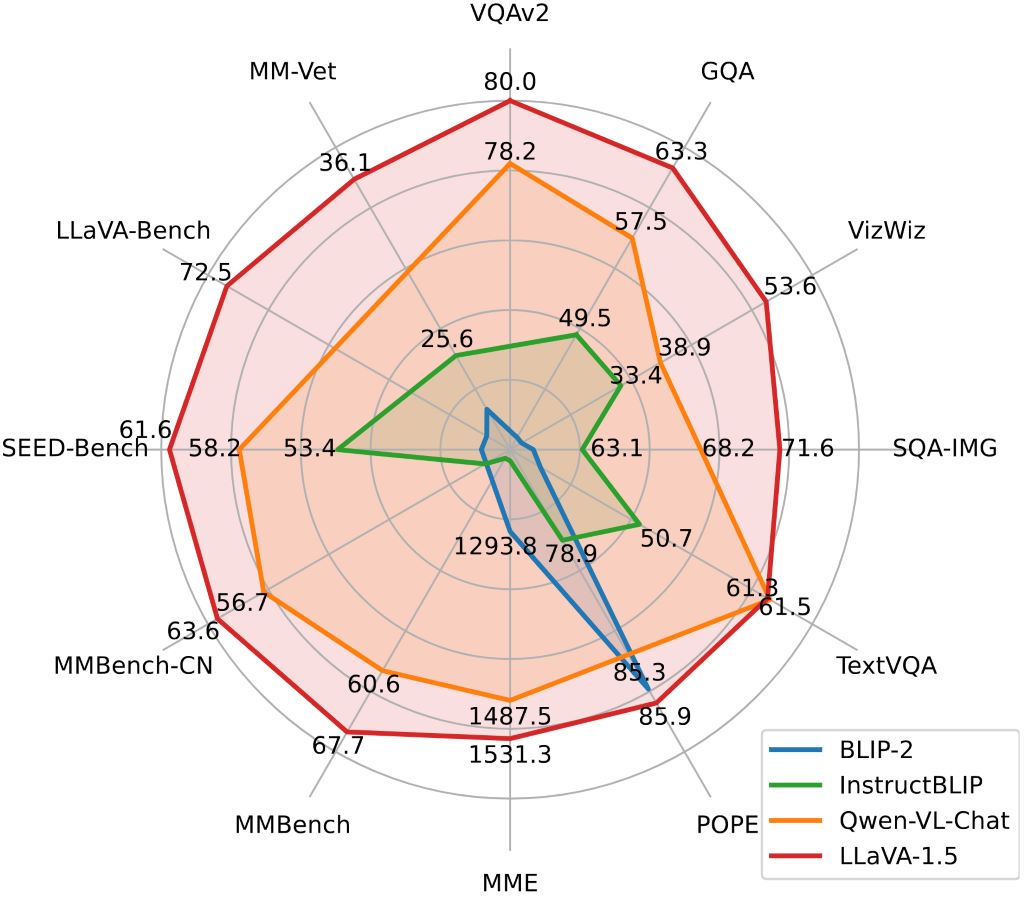
LLaVA-v1.5-13B excels in processing and synthesizing information from both text and images, outperforming GPT-4 in some tests.
More info LLaVA project website.